Updrading Ignition to the latest (8.1.42, as of this writing) will update POI from 3.1.7 to 4.1.2.
When I originally posted this question, it took me awhile to find a solution that worked for me. I have only used it on one project the whole time. My solution was to copy each column in to a dataset from the excel sheet. I created a screen with a table that displays the dataset and a submit button. The submit button has a simple script to insert it into the database table. In the end it was a work around but it worked.
Screen Shot

Script
#imports
import system
#get data from dataset
data = event.source.parent.getComponent('Table').data
for insertrow in range(0,data.getRowCount()):
query = "INSERT INTO PartsLocation(Location) VALUES(?)"
args = [data.getValueAt(insertrow, 0)]
system.db.runPrepUpdate(query, args)
I have upgraded Ignition and now it seems to work... Really strange ![]()
How to link excel to dataset function filepath with the file upload component. Actually i am trying to pass the file path dynamically so user will be able to select the file path
You cannot supply a file path to an Upload component. That would be malware-ish behavior. The user must always control where the file comes from in their system.
nice job @JordanCClark , it works with the example files but i´ve a file with the next sequenece
test.xlsx (10.4 KB)
i try change to diferent formats but i can´t find the issue.
Your first column has differing datatypes. Excel doesn't give a wet slap what you format the cells for.
I have revamped the processing a bit. You can find it on my GitHub page.
Assuming you use the same package structure I show there, the functions of interest will be:
- util.dataset.fromExcel()
- util.dataset.fromExcelBytes() -- useful for using with perspective
- util.dataset.processExceltoDataset()
system.dataset.toDataSet(headers,data) does not like different cellTypes in the same column when it converts to a Dataset. I don't care so much for numbers being numbers until after I'm handling aggregation within the dataset. I came across the same issue you had. Here is how I fixed it.
if cellType == 'NUMERIC':
if DateUtil.isCellDateFormatted(cell):
value = cell.dateCellValue
else:
value = str(cell.getNumericCellValue())
elif cellType == 'STRING':
value = cell.getStringCellValue()
From the Documentation on XSSFCell(POI API Documentation)
XSSF API Documentation
"public java.lang.String getStringCellValue()
Get the value of the cell as a string
For numeric cells we throw an exception. For blank cells we return an empty string. For formulaCells that are not string Formulas, we throw an exception
Returns:
the value of the cell as a string"
Hi,
the following is the data i’ve stored in excel -

and i get this error -

def excelToDataSet(fileName, hasHeaders = False, sheetNum = 0, firstRow = None, lastRow = None, firstCol = None, lastCol = None):
import org.apache.poi.ss.usermodel.WorkbookFactory as WorkbookFactory
import org.apache.poi.ss.usermodel.DateUtil as DateUtil
from java.io import FileInputStream
from java.util import Date
"""
Function to create a dataset from an Excel spreadsheet. It will try to automatically detect the boundaries of the data,
but helper parameters are available:
params:
fileName - The path to the Excel spreadsheet. (required)
hasHeaders - If true, uses the first row of the spreadsheet as column names.
sheetNum - select the sheet to process. defaults to the first sheet.
firstRow - select first row to process.
lastRow - select last row to process.
firstCol - select first column to process
lastCol - select last column toprocess
"""
fileStream = FileInputStream(fileName)
wb = WorkbookFactory.create(fileStream)
sheet = wb.getSheetAt(sheetNum)
if firstRow is None:
firstRow = sheet.getFirstRowNum()
if lastRow is None:
lastRow = sheet.getLastRowNum()
data = []
for i in range(firstRow , lastRow + 1):
row = sheet.getRow(i)
print str(i).zfill(3), list(row)
if i == firstRow:
if firstCol is None:
firstCol = row.getFirstCellNum()
if lastCol is None:
lastCol = row.getLastCellNum()
else:
# if lastCol is specified add 1 to it.
lastCol += 1
if hasHeaders:
headers = list(row)[firstCol:lastCol]
else:
headers = ['Col'+str(cNum) for cNum in range(firstCol, lastCol)]
rowOut = []
for j in range(firstCol, lastCol):
if i == firstRow and hasHeaders:
pass
else:
cell = row.getCell(j)
system.perspective.print(i)
system.perspective.print(j)
system.perspective.print(cell)
cellType = cell.getCellType().toString()
system.perspective.print(cellType)
if cellType == 'NUMERIC':
if DateUtil.isCellDateFormatted(cell):
value = cell.dateCellValue
else:
value = cell.getNumericCellValue()
if value == int(value):
value = int(value)
elif cellType == 'STRING':
value = cell.getStringCellValue()
elif cellType == 'BOOLEAN':
value = cell.getBooleanCellValue()
elif cellType == 'BLANK':
value = None
elif cellType == 'FORMULA':
formulatype=str(cell.getCachedFormulaResultType())
if formulatype == 'NUMERIC':
if DateUtil.isCellDateFormatted(cell):
value = cell.dateCellValue
else:
value = cell.getNumericCellValue()
if value == int(value):
value = int(value)
elif formulatype == 'STRING':
value = cell.getStringCellValue()
elif formulatype == 'BOOLEAN':
value = cell.getBooleanCellValue()
elif formulatype == 'BLANK':
value = None
else:
value = None
rowOut.append(value)
if len(rowOut) > 0:
data.append(rowOut)
fileStream.close()
return system.dataset.toDataSet(headers, data)
fName = 'C:/Program Files/Inductive Automation/Ignition/data/excel/readExcel4.xlsx'
ds1 = excelToDataSet(fName, True)
self.getSibling("Table").props.data = ds1
Haven’t made any changes in the code except adding a few print statements to debug…
This happens after accessing the row 2 cells when an empty cell is encountered, not sure what to add/change in the code?
Sorry for the late reply. Spending a few days off for the Thanksgiving holiday.
Can you post the file that you’re having issues with?
Do you mean the Excel file?
test.xlsx (8.7 KB)
Edit: Ran the code for this on your github, i got the right output, with one caveat i.e., it works if none of the cells are Null.
what do i need to change for the code to work even for cells with nothing in them?
Error:
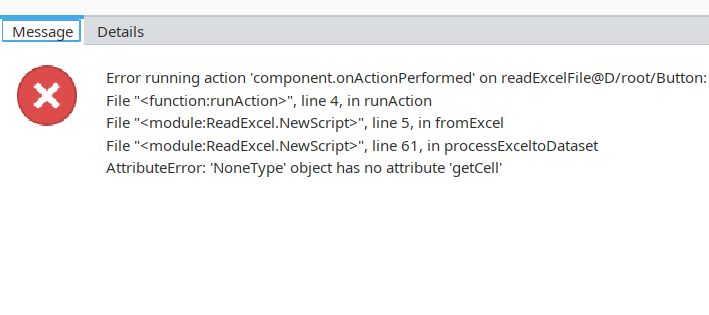
Seems to have trouble with single column datasets in Excel. I updated processExceltoDataset() to handle that.
Yess that worked! Thanks a lot! ![]()
Hi,
Had to make a few changes to processExcelToDataset() which included checking the limits of integers and long values. Please look out for comments with ‘Edit’.
def fromExcel(fileName, hasHeaders = False, sheetNum = 0, firstRow = None, lastRow = None, firstCol = None, lastCol = None, pyDataSet = False):
from java.io import FileInputStream
fileStream = FileInputStream(fileName)
print type(fileStream)
return processExceltoDataset2(fileStream, hasHeaders, sheetNum, firstRow, lastRow, firstCol, lastCol, pyDataSet)
def processExceltoDataset(streamIn, hasHeaders = False, sheetNum = 0, firstRow = None, lastRow = None, firstCol = None, lastCol = None, pyDataSet = False):
import org.apache.poi.ss.usermodel.WorkbookFactory as WorkbookFactory
import org.apache.poi.ss.usermodel.DateUtil as DateUtil
from java.util import Date
from com.inductiveautomation.ignition.common.util import DatasetBuilder
from java.lang import String, Integer, Long, Boolean, Float, Double
"""
Function to create a dataset from an Excel spreadsheet. It will try to automatically detect the boundaries of the data,
but helper parameters are available:
params:
streamIn - The input stream of the Excel spreadsheet. (required)
hasHeaders - If true, uses the first row of the spreadsheet as column names.
sheetNum - select the sheet to process. defaults to the first sheet.
firstRow - select first row to process.
lastRow - select last row to process.
firstCol - select first column to process
lastCol - select last column to process
pyDataSet - return a PyDataSet
"""
wb = WorkbookFactory.create(streamIn)
sheet = wb.getSheetAt(sheetNum)
if firstRow is None:
firstRow = sheet.getFirstRowNum()
if lastRow is None:
lastRow = sheet.getLastRowNum()
typeList = []
data = []
for i in range(firstRow , lastRow + 1):
row = sheet.getRow(i)
if i == firstRow:
if firstCol is None:
firstCol = row.getFirstCellNum()
if lastCol is None:
lastCol = row.getLastCellNum()
else:
# if lastCol is specified add 1 to it.
lastCol += 1
colValues = [[] for idx in range(firstCol, lastCol)]
colTypes = [None] * len(colValues)
if hasHeaders:
headers = list(row)[firstCol:lastCol]
else:
headers = ['Col'+str(cNum) for cNum in range(firstCol, lastCol)]
rowOut = []
for idx, j in enumerate(range(firstCol, lastCol)):
if i == firstRow and hasHeaders:
pass
else:
if row is None:
value = None
else:
cell = row.getCell(j)
if cell is not None:
cellType = cell.getCellType().toString()
if cellType == 'FORMULA':
cellType=str(cell.getCachedFormulaResultType())
else:
cellType = cell.getCellType().toString()
if cellType == 'NUMERIC':
if DateUtil.isCellDateFormatted(cell):
value = cell.dateCellValue
if colTypes[idx] is None:
colTypes[idx] = Date
else:
value = cell.getNumericCellValue()
if colTypes[idx] is None:
if value == int(value):
intVal = int(value) # Check range for Integer # Start Edit 1
if -2147483648 <= intVal <= 2147483647:
colTypes[idx] = Integer
elif -9223372036854775808 <= intVal <= 9223372036854775807:
colTypes[idx] = Long
else:
colTypes[idx] = Double # End Edit 1
else:
colTypes[idx] = Double
else:
if colTypes[idx] == Integer: # Edit 3
if value != int(value):
colTypes[idx] = Double
else:
intVal = int(value)
if not (-2147483648 <= intVal <= 2147483647):
colTypes[idx] = Long
elif colTypes[idx] == Long:
if value != int(value):
colTypes[idx] = Double # End Edit 3
elif cellType == 'STRING':
if len(cell.getStringCellValue()) > 0:
value = cell.getStringCellValue()
if colTypes[idx] is not String:
colTypes[idx] = String
else:
value = None
elif cellType == 'BOOLEAN':
value = cell.getBooleanCellValue()
if colTypes[idx] is None:
colTypes[idx] = Boolean
elif cellType == 'BLANK':
value = None
else:
value = None
else:
value = None
rowOut.append(value)
colValues[idx].append(value)
if len(rowOut) > 0:
data.append(rowOut)
streamIn.close()
# Normalize column data
for i, colType in enumerate(colTypes):
if colType is Integer:
newCol = []
for col in colValues[i]:
if col is None:
newCol.append(None)
else:
newCol.append(int(col))
colValues[i] = newCol
elif colType is Long: # Start Edit 2
newCol = []
for col in colValues[i]:
if col is None:
newCol.append(None)
else:
newCol.append(long(col)) # Jython long
colValues[i] = newCol # End Edit 2
elif colType is String:
newCol = []
for col in colValues[i]:
if type(col) is float and col.is_integer():
newCol.append(unicode(int(col)))
else:
newCol.append(unicode(col))
colValues[i] = newCol
if len(headers) == 1:
data = [[value] for value in colValues[0]]
if pyDataSet:
return system.dataset.toPyDatSet(system.dataset.toDataSet(headers, data))
else:
return system.dataset.toDataSet(headers, data)
builder = DatasetBuilder.newBuilder()
builder.colNames(headers)
builder.colTypes(colTypes)
for row in zip(*colValues):
builder.addRow(list(row))
#dsOut = builder.build()
if pyDataSet:
#return system.dataset.toPyDataSet(system.dataset.toDataSet(headers, data))
return system.dataset.toPyDataSet(builder.build())
else:
#return system.dataset.toDataSet(headers, data)
return builder.build()
When i run this code against the attached excel, i get the following error -
com.inductiveautomation.ignition.common.script.JythonExecException
Traceback (most recent call last):
File "<function:runAction>", line 5, in runAction
File "<module:CSF.RAIL.CupConeManualImport.GetCupData>", line 5, in fromExcel
File "<module:CSF.RAIL.CupConeManualImport.GetCupData>", line 174, in processExceltoDataset
java.lang.ClassCastException
java.lang.ClassCastException: java.lang.ClassCastException
caused by org.python.core.PyException
Traceback (most recent call last):
File "<function:runAction>", line 5, in runAction
File "<module:CSF.RAIL.CupConeManualImport.GetCupData>", line 5, in fromExcel
File "<module:CSF.RAIL.CupConeManualImport.GetCupData>", line 174, in processExceltoDataset
java.lang.ClassCastException
java.lang.ClassCastException: java.lang.ClassCastException
caused by ClassCastException
The following snippet is calling the processExcelToDataset within a button -
filename = self.parent.custom.uploadedFileName
lastRow = self.getSibling("QuantityNum").props.text
filepath = 'C:\\Program Files\\Inductive Automation\\Ignition\\webserver\\webapps\\main\\CupConeBatchExcels\\CupBatchDetails\\'+filename
ds1 = CSF.RAIL.CupConeManualImport.GetCupData.fromExcel(filepath,True,firstRow = 4,lastRow = 20,firstCol = 0,lastCol=1)
self.getSibling("Table").props.data = ds1
Copy of Cup_test.xlsx (10.6 KB)
Hey, why are you importing all those data types in the second function?
Took the code from this post, i believe it is supposed to recognize each cell’s type
It's to work with defining column types with DatasetBuilder()
Yeah, but imports belong in project library scripts, outside any function. No exceptions.
It was originally posted as a proof of concept, not a finished product. C'est la vie, my friend. ![]()