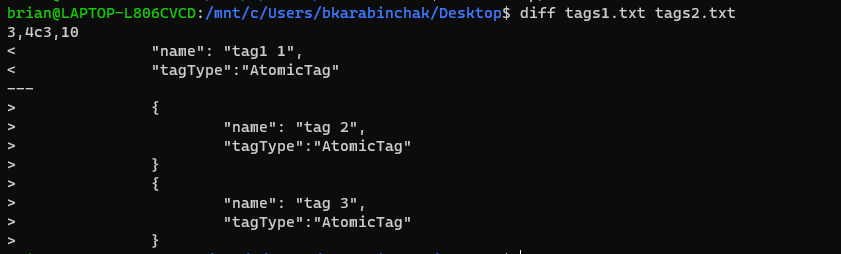
Ah you’re right notepadd++ won’t be able to do it.
Using an diff in linux provides the almost expected results though (looks slightly weird and perhaps I messed up my text file but its obvious which side the tags belong to)
but... again, diff-ing with a generic JSON compare tool is impossible unless there are the same tags present in both JSON files and they're in the same indexes in the arrays. There's no way around this, regardless of how the JSON is arranged. I wrote a script a while back to do this comparison and it's a pita, but definitely possible, and definitely needs specific code for Ignition tag JSON
Yea not in a notepad++/generic json tool right. But if the unique tag id that’s stored in the database was included as part of the json data, it seems vey doable with a script and perhaps should be part of a module or something they provide as a built in feature.
Just to follow up on this, I have created a feature request to add something like this to Ignition.
At this point (and as far as future plan go), tag definitions are stored in a SQLite DB in individual rows and loaded into memory so everything that you are likely using for making this comparison currently is based on what is pulled from Ignition’s memory. While there are things that Phil mentioned that could be done to order the output, there is also a performance cost associated with doing so. While we can look at making the output ordered in a consistent manner, forcing what could be 500k+ tags to return in an ordered manner is likely going to use a good amount more memory. A dedicated tool is probably something we should be investing in.
Garth
A SQLite index on path and name would probably suffice, and might not be as ugly performance-wise as you think.
Hopefully for v8.2 or so, the source of truth will be JSON on disk instead of in SQLite. If so, please consider using a hierarchy where tag folders are actual folders on disk, UDT definitions and instances are one file each with contents ordered by name, and all other leaf tags in a folder are in a single JSON file, ordered by name.
Make all json diff-friendly with tidyjson/jsonlint/whatever.
Use "version sort" or AlphaNumComparator so numbers in tag names are ordered the way humans like.
This above will be very git-friendly and, since each file will be sorted only when edited, should not present a performance problem at other times.
Meh. Applicable in bulk only on startup. Parallelizable where SQLite is not. With the suggested hierarchy, edits are confined to a limited target space. Putting leaf tags in one file per folder also helps.
Oh, and memory tag persistent values/timestamps should not be in the same hierarchy. Might even be best to keep those in a DB, with just a primary key saved in the JSON.
Hi there! Our design team at Inductive Automation is interested to hear about your experiences with this Tag Report Tool so far, now that the feature has been available for a while. We would appreciate it if you could spend a few minutes (approx. 5 mins) completing our survey. Thank you very much and have a wonderful day!
That is a Qualified Value, which is a Tag value that has three attributes; Value, Quality, and TimeStamp. You will need to reference value with .value.
What exactly does your question have to do with the tag report tool by the way?
Value in the Tag Report Tool is currently returning a qualified value as noted above by @jlandwerlen. We are working on a polish ticket where we are addressing this so that the individual aspects of the qualified value can be searched for.
@jlandwerlen I copied that value straight from the Tag Report Tool, trying to build a report to show just tags where the value >= x. but it failed everytime bc the value is a Qualified Value, as you pointed out.
So when you run the tool, you are presented with an option to copy as script. I haven’t tried, but you could get the raw results then check the value then and use that data in your report.
@jlandwerlen thanks for the tip. we were really just playing around with the new tool and hit that road block. not in a rush to implement anything with it. looks like there is a lot of potential tho.
Just an update on all the feedback that has been presented. We have just merged the polish ticket that will be available in nightlies starting tomorrow (9/10) and will be part of the 8.1.21 release. Some of the items (a few mentioned in this post) that are fixed/added:
Values and Timestamps of tags can be explicitly searched for
Alarm definitions are being consistently returned in the results
A column can be added to display a list of overridden properties
If you are deleting tags, the number of tags being deleted is accurate
Ability to include/non-include UDT members in the search results
Ability to include UDT definitions in the search results
Folders and UDT instances are no longer returning when Uncertain quality is looked for
If the Tag Report tool is closed, the settings you had are persisted when it is reopened
A NOT LIKE search has been added
Various UI fixes regarding column sizing and field display issues
I am hoping this improves on what we have already built.
Sounds great! Looking forward to using this in the future
Will there (or are there already) be context menu actions available on certain things that let you pre-fill and search based on the thing selected?
e.g.
right click on tag, select “find usage”
right click on UDT instance, select “find Definition usage”
right click on UDT Definition, select “find usage”
etc.
The same thing would be extremely useful for Views as well,
right click on View, select “find usage” (e.g. for views that are embedded)
The inverse for both would also be good, to find dependencies, although a little harder to implement.
Dependencies would include anything from script libraries used, embedded views used (and nested views inside of these), styles, etc. within the View you selected. For tags, this would include script libraries (for event handlers), alarm pipelines, history providers/db, UDT definitions, etc.
Vote here: Report tool to show dependencies of views/windows/templates/tags | Voters | Inductive Automation
In addition to this would also be great to be able to then export objects and include their dependencies. At the moment, it’s a real pain to package some Views up if they have multiple dependencies, especially if you don’t know what they are off the top of your head! It usually takes a few exports to get it right sometimes.
Vote here: Export component *with dependencies* | Voters | Inductive Automation
This reply has gotten a bit off-topic… so I’ve created separate topics for these as well as ideas
This is coming, it is something we are testing as this point but was contingent on these changes getting merged. Might not be exactly as you are describing, but will achieve the same results.
Dependancies is something we are working towards, but it is going to be a little while before it is ready for production.
I've finally had the chance to put this tool to use, and it's super cool! I love all the fields that you can add into the table, and all of the filtering customisations are very useful and appreciated!
Thanks guys and gals for all your hard work.
Edit:
One extra column option that would be good would be to have Type Id to which the tag belongs to. To be extra annoying, if the tag is part of a UDT that is nested in another UDT, it would be great to show this AND be able to edit the underlying UDT definitions directly.
E.g. Column "Type Id' displayed value: _types_/Devices/Pump 1 -> _types_/Devices/Pump Common -> _types_/Devices/Some other UDT
Right clicking on the Type Id value would show a context menu with options:
Edit _types_/Devices/Pump 1 Definition
Edit _types_/Devices/Pump Common Definition
Edit _types_/Devices/Some other UDT Definition
And obviously the option to edit the instance as well, which is the default edit option now