We have a system where we have our ignition communicating with multiple AB PLC devices as well as OPC servers hosted externally on other VMs. We have tags that are read and written both ways and are tied to driven tag group. The Write Operation is using “WriteSynchronous” method.
Here’s a snippet from the wrapper log that shows the delay:
INFO | jvm 1 | 2021/08/12 10:38:40 | Updating [default]AP/Filler_8/Write:5 to new value of 4142. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_5_
INFO | jvm 1 | 2021/08/12 10:38:40 | Updating [default]AP/Filler_8/Write:1 to new value of 0. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:42 | Updating [default]AP/Filler_8/Write:5 to new value of 4143. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_5_
INFO | jvm 1 | 2021/08/12 10:38:42 | Updating [default]AP/Filler_8/Write:1 to new value of 1. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:44 | Updating [default]AP/Filler_8/Write:1 to new value of 0. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:45 | Updating [default]AP/Filler_8/Write:5 to new value of 4144. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_5_
INFO | jvm 1 | 2021/08/12 10:38:46 | Updating [default]AP/Filler_8/Write:1 to new value of 1. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:49 | Updating [default]AP/Filler_8/Write:1 to new value of 0. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:51 | Updating [default]AP/Filler_8/Write:5 to new value of 4145. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_5_
INFO | jvm 1 | 2021/08/12 10:38:51 | Updating [default]AP/Filler_8/Write:1 to new value of 1. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:54 | Updating [default]AP/Filler_8/Write:1 to new value of 0. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:56 | Updating [default]AP/Filler_8/Write:5 to new value of 4146. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_5_
INFO | jvm 1 | 2021/08/12 10:38:56 | Updating [default]AP/Filler_8/Write:1 to new value of 1. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:38:58 | Updating [default]AP/Filler_8/Write:1 to new value of 0. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:39:01 | Updating [default]AP/Filler_8/Write:5 to new value of 4147. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_5_
INFO | jvm 1 | 2021/08/12 10:39:01 | Updating [default]AP/Filler_8/Write:1 to new value of 1. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
INFO | jvm 1 | 2021/08/12 10:39:04 | Updating [default]AP/Filler_8/Write:1 to new value of 0. Source Tag is [default]Fillers/Filler8/OTTO_OUT/OTTO_OUT_1_
On the PLC side, the Write:5 value is being incremented by 1 every 2 seconds. However, in the wrapper log I only see it updated every 5 - 6 seconds. Over a span of a few minutes, the values seem to be off by 1-2 mins and leads to many issues across the entire system.
Below is an example of the system actually functioning fine and updating the tags ~every 2 seconds, even though in some cases it takes 1 second more or less:
INFO | jvm 1 | 2021/08/12 11:42:52 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7069. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:42:53 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7070. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:42:55 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7071. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:42:57 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7072. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:42:59 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7073. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:43:02 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7074. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:43:02 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7075. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:43:05 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7076. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:43:07 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7077. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
INFO | jvm 1 | 2021/08/12 11:43:09 | Updating [default]AP/Human_Filler_101/Write:5 to new value of 7078. Source Tag is [default]Supervisor/Filler101/OTTO_OUT_FILLER_101/OTTO_OUT_FILLER_101_5_
Is there something associated with the driven tag group settings that can cause this? I have over 18 driven tag groups, each one being driven by the value of an OPC tag associated with one of the OPC servers we’re connecting to. This issue occurs randomly every few days and sometimes resolves itself over time and sometimes requires us to restart the gateway or OPC connection. There are no errors that I see in the wrapper log when this occurs.
Looking for some advice or support to understand what we should be checking.
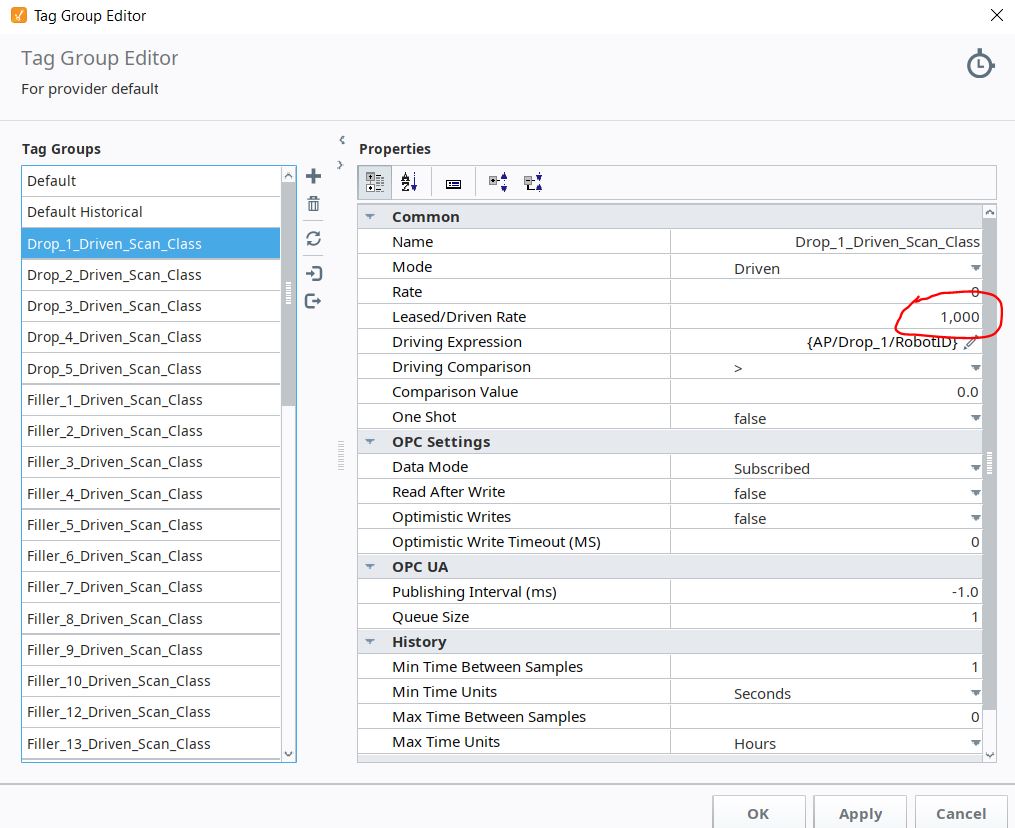
Update on the issue above. We actually have 46 driven tag groups. Each monitoring a tag from an OPC connection to an external server and evaluating the tag value to be > 0 and driving 16 tags from AB PLC(s). Each driven tag group was setup to 1.1 second leased/driven rate instead of 1 second that I wanted (likely a typo during setup). And the Rate is set to 0 so as to not poll the driven tags when the comparison is not true. Please see the 2 attached images. I updated the leased/driven rate to 1 second.
Could this rate of 1.1 second be causing the delay in the values being updated over time. The values from the driven tags that I’m logging are being written synchronously. That said, the driving tag is likely only ever active for 30 seconds at a time and then probably doesn’t get triggered again for a few minutes. So it’s not like we have a continuous operation occurring for hours that should lead to this delay.
Alternatively, can multiple driven tag groups being active at the same time lead to issues? Say 20-30 of them?
What’s printing those log messages? A tag event script?
You say the PLC is incrementing those values every 2 seconds, but even with the logs 5 seconds apart you don’t have any gaps in the value, so it seems like the OPC and Tag Groups part are fine and maybe your system is periodically seeing a burst of tag event changes or the queue is otherwise backed up?
Yes tag event script prints those commands. We monitored the PLC and it seems like it’s updating at the correct interval. However, the execution at the OPC layer and ignition write seems to be delayed. Could this queue be occurring on ignition? I agree that the we’re not missing any values. Every consecutive value is being updated. However it’s just not happening at the time when the value updates on the PLC
Yes, tag events are queued for execution and consumed by up to 3 threads. If there are a lot of tag changes causing tag event scripts to execute and/or they are taking a long time to execute then the queue can grow and executions slow down.
If this happens regularly and for long enough that you can go to the threads page to get a thread dump next time that may help verify this.
Ok. Could WriteSynchronous execution instead of just Write have anything to do with this? Can you confirm that the Lease/Driven Rate that I mentioned before is not the issue then?
Is it possible to get a thread dump from a past event that occurred? This seems to occur for 20-30 minutes when it does but only happens every few days usually. It happened 3 times today. I see that I can find it under Diagnostics → Threads.
Ok. The challenge with capturing this live is that it is impacts a 24x7 production facility and their automation significantly when it happens. Is there any alternate way to find the root cause? We have the system down now due to this issue and a customer that may not be willing to bring it back up until we have a root cause.
Also, could Print statements that are doing the logging cause issues? I’ve done this on other systems and this hasn’t been an issue but in the other systems, I don’t use driven tag groups. I feel like this has something to do with this setup and have no way to compare against another similar setup because we don’t use 1.
Also important thing to note is that this is only impacting data that is connected to Driven Tags (From PLC to OPC Server). The data other way around (From OPC server to PLC) seems to be going through without the same delays. They are just a part of the default tag group.
Well there are a few gateway event scripts being executed every second by these driven tags which are monitoring multiple tags at the gateway level. I’m not sure what is classified as too many scripts. On average, when I look at my wrapper log, I see 12-15 updates per second.
Thanks for the support today. I’ll report back tomorrow once the system is running again. If your hunch about the queue size is correct, then how do we go about remedying that? Also, where will the debug log items show up? In the wrapper log itself?
Correction on 1 thing I stated above: The delay is also happening on tags that are not using driven tag groups based on a comparison that we did against logs from our OPC server for when the value changed and when it was logged by ignition event script. So looks like checking the queue to get a better idea is the next steps and it doesn’t look like it has to do with the driven tag settings.
If it does turn out to be the tag event script queue then there’s a parameter that can be tuned to increase the number of threads that service it, but that should only be done after you’ve called support so they can look at your scripts with you and try to figure out why they’re taking so long to execute (or why there are so many that it gets backed up sometimes).
Kevin, is it possible that the IPV6 connection could be causing issues? What’s the best way to disable this on the Linux Ubuntu Machine specifically to Java isn’t trying to listen to devices on tcp6? One of the networking personnel installed netstat on the linux machine and is seeing java try to listen to tcp6. Here’s a sample attached.