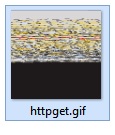
Can anyone tell me why urllib2.urlopen takes so long to fetch file/binary data from a website while system.net.httpGet fetches data quickly. I’m talking apples vs. oranges here because httpGet doesn’t work well with binary data and that’s what I need. Take for example this file https://i.imgur.com/BcN64PR.gif. Its an animated gif. If I use httpGet, I’ll either get a scrambled animation or just the single frame. if I use urllib2.urlopen() followed by .read()…and subsequent StringUtil.toBytes(), then I get the complete file intact just as you would in a browser but takes nearly 5 seconds for code to run.
FWIW, I have read through a mind numbing posts across the web of other folks using ImageIO or ByteArrayOutputStreams or InputStreams…but with no success for me. urllib2 works…but very slow.
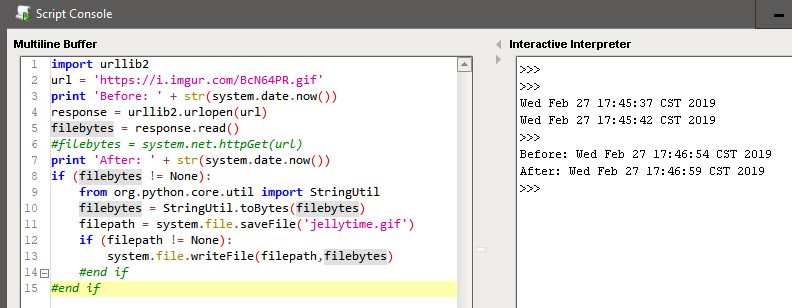
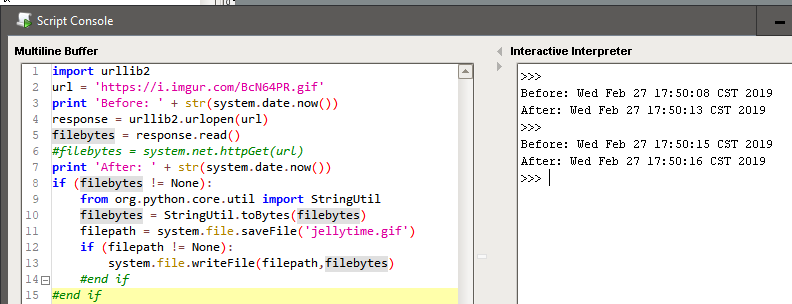
Try running this in a script console and check out the file.
import urllib2
url = 'https://i.imgur.com/BcN64PR.gif'
#response = urllib2.urlopen(url)
#filebytes = response.read()
filebytes = system.net.httpGet(url)
if filebytes != None:
#from org.python.core.util import StringUtil
#filebytes = StringUtil.toBytes(filebytes)
filepath = system.file.saveFile("peanutbutterjellytime.gif")
system.file.writeFile(filepath,filebytes)
#end if
This is what httpGet 's you.
{kind=link}